 Hadoop is an open source framework built to store and process data (Big Data) in distributed environments, in a cluster of computers each having computational power and storage. This distributed cluster of computers are meant to solve the scaling of data day by day.
Hadoop is an open source framework built to store and process data (Big Data) in distributed environments, in a cluster of computers each having computational power and storage. This distributed cluster of computers are meant to solve the scaling of data day by day.
Some of the key terminology that I will be discussing are Big Data, MapReduce algorithm, and Hadoop Distributed File System.
So, let’s get started……..
We used to have floppy disks and some 20GB of computer hard disk, say around 20 years back. We have slowly moved or were forced to use CD/DVD and then to memory card/Pendrive and about 1TB of hardisk. Now, it has all moved to 128GB pendrive/memory card, 4TB of HD and cloud storage.![]()
The data that gets uploaded to networking sites have increased with the recent advancement in technology and the ease of its availability.
This has caused us to move from traditional storage to an advanced level of cloud storage.
If you just browse on internet, regarding the amount of data that gets uploaded and downloaded to some of the Giant companies like Google, Facebook, Linkdin. You won’t be surprised, because you already know it.
So, the question remains here is, how do this tech giants handle such massive amount of data and give a quick response when asked for it through browser. I know that you will be thinking of storing in very large system. Yes, its not incorrect, but how do they handle it?
Here comes the solution for all, ie Hadoop.
What is Big Data?
Big data means really a big data, it is a collection of large datasets that cannot be processed using traditional computing techniques. Big data is not merely a data, rather it has become a complete subject, which involves various tools, technqiues and frameworks.
What Big Data comprises of?

- Black Box Data : It is a component of helicopter, airplanes, and jets, etc. It captures voices of the flight crew, recordings of microphones and earphones, and the performance information of the aircraft.
- Social Media Data : Social media such as Facebook and Twitter hold information and the views posted by millions of people across the globe.
- Stock Exchange Data : The stock exchange data holds information about the ‘buy’ and ‘sell’ decisions made on a share of different companies made by the customers.
- Power Grid Data : The power grid data holds information consumed by a particular node with respect to a base station.
- Transport Data : Transport data includes model, capacity, distance and availability of a vehicle.
- Search Engine Data : Search engines retrieve lots of data from different databases.
Thus Big Data includes huge volume, high velocity, and extensible variety of data. The data in it will be of three types.
- Structured data : Relational data.
- Semi Structured data : XML data.
- Unstructured data : Word, PDF, Text, Media Logs.
What are the benifits of Big Data?
Big data is really critical to our life and its emerging as one of the most important technologies in modern world. Follow are just few benefits which are very much known to all of us:
- Using the information kept in the social network like Facebook, the marketing agencies are learning about the response for their campaigns, promotions, and other advertising mediums.
- Using the information in the social media like preferences and product perception of their consumers, product companies and retail organizations are planning their production.
- Using the data regarding the previous medical history of patients, hospitals are providing better and quick service.
History of Hadoop?
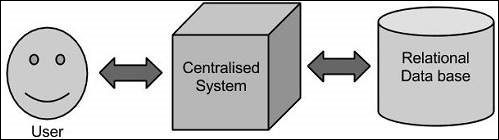
Traditional Approach
In this approach, an enterprise will have a computer to store and process big data. Here data will be stored in an RDBMS like Oracle Database, MS SQL Server or DB2 and sophisticated softwares can be written to interact with the database, process the required data and present it to the users for analysis purpose.
Limitation
This approach works well where we have less volume of data that can be accommodated by standard database servers, or up to the limit of the processor which is processing the data. But when it comes to dealing with huge amounts of data, it is really a tedious task to process such data through a traditional database server.
Google’s Solution
Google solved this problem using an algorithm called MapReduce. This algorithm divides the task into small parts and assigns those parts to many computers connected over the network, and collects the results to form the final result dataset.
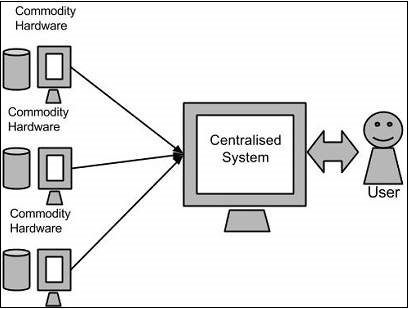
Above diagram shows various commodity hardwares which could be single CPU machines or servers with higher capacity.
Hadoop
Anf then, Doug Cutting, Mike Cafarella and team took the solution provided by Google and started an Open Source Project called HADOOP in 2005 and Doug named it after his son’s toy elephant. Now Apache Hadoop is a registered trademark of the Apache Software Foundation.
Hadoop runs applications using the MapReduce algorithm, where the data is processed in parallel on different CPU nodes. In short, Hadoop framework is capable enough to develop applications capable of running on clusters of computers and they could perform complete statistical analysis for a huge amounts of data.
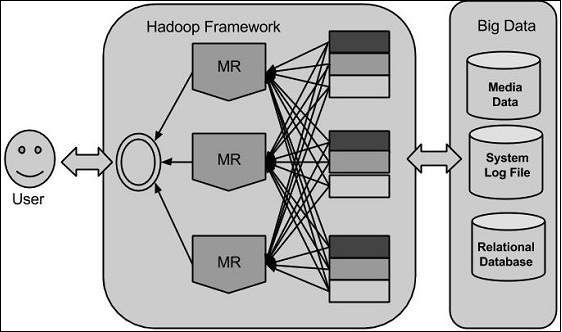
Hadoop is an Apache open source framework written in java that allows distributed processing of large datasets across clusters of computers using simple programming models. A Hadoop frame-worked application works in an environment that provides distributed storage and computation across clusters of computers. Hadoop is designed to scale up from single server to thousands of machines, each offering local computation and storage.
Hadoop Architecture
Hadoop framework includes following four modules:
- Hadoop Common: These are Java libraries and utilities required by other Hadoop modules. These libraries provides filesystem and OS level abstractions and contains the necessary Java files and scripts required to start Hadoop.
- Hadoop YARN: This is a framework for job scheduling and cluster resource management.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop MapReduce: This is YARN-based system for parallel processing of large data sets.
We can use following diagram to depict these four components available in Hadoop framework.

Hadoop framework includes following four modules:
- Hadoop Common: These are Java libraries and utilities required by other Hadoop modules. These libraries provides filesystem and OS level abstractions and contains the necessary Java files and scripts required to start Hadoop.
- Hadoop YARN: This is a framework for job scheduling and cluster resource management.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop MapReduce: This is YARN-based system for parallel processing of large data sets.
We can use following diagram to depict these four components available in Hadoop framework.
The whole architecture needs separate blog post to explain each module. Here I will be explaining each module briefly.
MapReduce
Hadoop MapReduce is a software framework for easily writing applications which process big amounts of data in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
The term MapReduce actually refers to the following two different tasks that Hadoop programs perform:
- The Map Task: This is the first task, which takes input data and converts it into a set of data, where individual elements are broken down into tuples (key/value pairs).
- The Reduce Task: This task takes the output from a map task as input and combines those data tuples into a smaller set of tuples. The reduce task is always performed after the map task.
Typically both the input and the output are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
The MapReduce framework consists of a single master JobTracker and one slave TaskTracker per cluster-node. The master is responsible for resource management, tracking resource consumption/availability and scheduling the jobs component tasks on the slaves, monitoring them and re-executing the failed tasks. The slaves TaskTracker execute the tasks as directed by the master and provide task-status information to the master periodically.
The JobTracker is a single point of failure for the Hadoop MapReduce service which means if JobTracker goes down, all running jobs are halted.
Hadoop Distributed File System
Hadoop can work directly with any mountable distributed file system such as Local FS, HFTP FS, S3 FS, and others, but the most common file system used by Hadoop is the Hadoop Distributed File System (HDFS).
The Hadoop Distributed File System (HDFS) is based on the Google File System (GFS) and provides a distributed file system that is designed to run on large clusters (thousands of computers) of small computer machines in a reliable, fault-tolerant manner.
HDFS uses a master/slave architecture where master consists of a single NameNodethat manages the file system metadata and one or more slave DataNodes that store the actual data.
A file in an HDFS namespace is split into several blocks and those blocks are stored in a set of DataNodes. The NameNode determines the mapping of blocks to the DataNodes. The DataNodes takes care of read and write operation with the file system. They also take care of block creation, deletion and replication based on instruction given by NameNode.
HDFS provides a shell like any other file system and a list of commands are available to interact with the file system.
How Does Hadoop Work?
Stage 1
A user/application can submit a job to the Hadoop (a hadoop job client) for required process by specifying the following items:
- The location of the input and output files in the distributed file system.
- The java classes in the form of jar file containing the implementation of map and reduce functions.
- The job configuration by setting different parameters specific to the job.
Stage 2
The Hadoop job client then submits the job (jar/executable etc) and configuration to the JobTracker which then assumes the responsibility of distributing the software/configuration to the slaves, scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
Stage 3
The TaskTrackers on different nodes execute the task as per MapReduce implementation and output of the reduce function is stored into the output files on the file system.
Advantages of Hadoop
- Hadoop framework allows the user to quickly write and test distributed systems. It is efficient, and it automatic distributes the data and work across the machines and in turn, utilizes the underlying parallelism of the CPU cores.
- Hadoop does not rely on hardware to provide fault-tolerance and high availability (FTHA), rather Hadoop library itself has been designed to detect and handle failures at the application layer.
- Servers can be added or removed from the cluster dynamically and Hadoop continues to operate without interruption.
- Another big advantage of Hadoop is that apart from being open source, it is compatible on all the platforms since it is Java based.
